CSV-Filter数据准备解读
该研究基于深度学习开发了结构变异过滤工具,针对short-read 和 long-read方法检测的结构变异位点,本博客主要关注方法和材料部分。
该研究也将结构变异过滤问题转化为图像二分类问题。那么首要问题还是如何将结构变异转化为图像,以及negative training sample,与其他类似研究一样,该研究同样基于CIGAR比对信息来编码图像,并将图像编码拆解成:
- Structural variant sites selecting;
- Reads selecting;
- Image coding。
下文将解析作者的处理。
Negative training samples preparing

作者通过分析结构变的分布,发现变异的长度符合泊松分布。作者计算变异长度的平均值,方差并计算这两者的调和平均数。将调和平均数作为密度函数的参数,遵循该分布,生成negative samples。
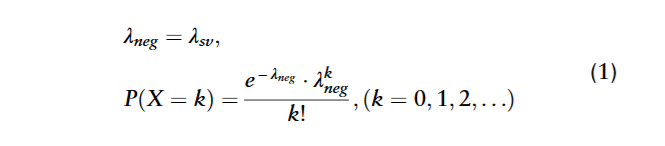
随后迭代生成负样本,如果生成的负样本和相邻的样本有超过一半的重合,那么应舍弃并重新生成。在完成迭代后,作者将产生的变异标准化。
图中,$\lambda_{sv}$ 应该truth set的sv长度的均值和方差的调和平均数
Sites locating
Reads selecting
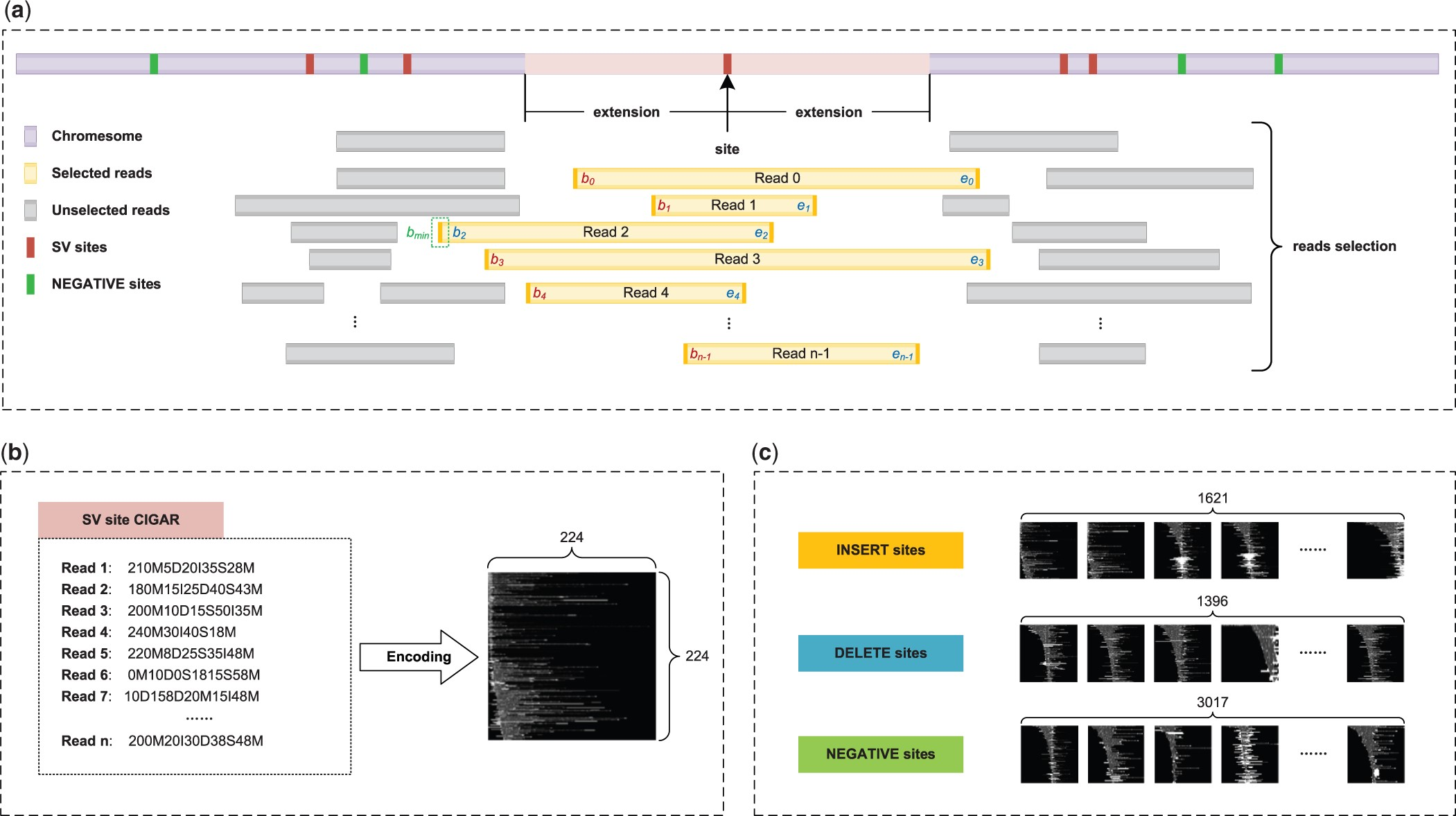
如图所示,在确定变异位点后,围绕变异位点进行reads选取。
从图a可以看出,作者在断点周围向上游和下游都扩展了一段extension,所有覆盖整个范围的reads将会被选择。
Image coding

在选取reads后,维护两个列表用于存储所有reads的起点和终点,确认所有reads起点中最小的,命名为:$b_{min}$ , 迭代所有reads,计算当前reads起点与$b_{min}$的偏移,确定当前reads编码的范围 ($b_{i} - b_{min},e_{i}$)。
在填充像素时,针对CIGAR中的”N”,”P”,”H”,”=”,”X” 以及偏移部分,填充0,上述reads编码范围部分使用kernal_cigar函数填充。
def kernel_cigar(read, ref_min, ref_max, cigar_resize, zoom):
cigars_img = torch.zeros([1, int((ref_max - ref_min) / zoom)])
max_terminal = read.reference_start - ref_min
Dataset
该研究主要使用两个样本(HG002, NA12878)的相关文件用于训练
HG002
- Third-generation data
三代测序数据使用minimap2, pbmm2, NGMLR比对到参考基因组 GRCh37
测序数据包括
PacBio CCs 15kb_20kb chemistry2(HIFI)
Oxford Nanopore ultralong(guppy-V3.2.4_2020-01-22)
- SV
该研究选用了GIAB(Genome in a Bottle)的benchmark数据集-HG002_SVs_Tier1_v0.6,该数据集包括4,199个deletions与5,442个insertions。
- bam
二代数据该研究使用来自HG002的illumina 300X,参考基因组为hs37d5。HG002.hs37d5.60x.1.bam
NA12878
- SV
有研究对NA12878的三代测序数据使用三种方法检测了结构变异,包括INS,DEL. vcf-file
同时该样本还有基于二代测序数据的结构变异数据集. vcf-file
- bam
PacBio 测序数据比对到hg19的bam文件. bam_file illumina测序数据比对到GRCh38的bam文件. bam_file
- reference
T2T-CHM13
该数据集用于验证,该数据集没有对应的gold standard dataset, 作者使用Dipcall(v0.3)对CHM13的端到端版本进行变异检测,将大于50bp且位于高可信区域的变异视为 ground truth
Ashkenazim Trio
作者还使用HG002, HG003, HG004统计CIGAR字符串中各个操作的比例. Archive data for the Ashkenazim Trio
Reference
[1] Xia Z, Xiang W, Wang Q, Li X, Li Y, Gao J, et al. CSV-Filter: a deep learning-based comprehensive structural variant filtering method for both short and long reads. Bioinformatics. 2024;40(9).
[2] Xiang W, Cui Y, Yang Y, Zhang A, Ji B, Peng S, editors. MSVF: Multi-task Structure Variation Filter with Transfer Learning in High-throughput Sequencing. 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM); 2022 6-8 Dec. 2022.
[3] Zook JM, Hansen NF, Olson ND, Chapman L, Mullikin JC, Xiao C, et al. A robust benchmark for detection of germline large deletions and insertions. Nat Biotechnol. 2020;38(11):1347-55.
……
本博客仅作为论文阅读笔记,学习过程的记录!